
As Andy Massick explains well, if you are making a few requests per day to a simple non-reasoning text based AI model the carbon impact is, to use a technical term, bugger all 1.
I probably ask ChatGPT and Claude around 8 questions a day on average. Over the course of a year of using them, this uses up the same energy as running a single space heater in my room for 2 hours in total. Not 2 hours per day, just a one-off use of a single space heater for 2 hours […] By being vegan, I have as much climate impact as not prompting ChatGPT 400,000 times each year
I want to try and explain how this is consistent with Eric Schmidt saying that energy use will massively multiply:
“People are planning 10 gigawatt data centers,” Schmidt said. “Gives you a sense of how big this crisis is. Many people think that the energy demand for our industry will go from 3 percent to 99 percent of total generation. One of the estimates that I think is most likely is that data centers will require an additional 29 gigawatts of power by 2027, and 67 more gigawatts by 2030. These things are industrial at a scale that I have never seen in my life.” 2
Assumptions Matter
To state the obvious, nearly everything we do is climate impacting so if you don’t think AI is useful or ethical, then by definition it’s an environmental disaster. I think this is core to a lot of the debate - people start from opposing positions right at the start, and then everything after that is post-hoc justification.
I’m starting from the assumption that AI is useful (it is to me!) and so that it’ll be used. I don’t know if we’ll develop super-human intelligence, but as I’ll discuss later, the people who forecast massive energy demands for AI absolutely do.
It’s also very important to separate out the wider use of “AI” from LLMs. Andy Massick again:
The services using 97-99% of AI’s energy budget are (roughly in order)
- Recommender Systems - Content recommendation engines and personalization models used by streaming platforms, e-commerce sites, social media feeds, and online advertising networks.
- Enterprise Analytics & Predictive AI - AI used in business and enterprise settings for data analytics, forecasting, and decision support.
- Search & Ad Targeting - The machine learning algorithms behind web search engines and online advertising networks.
- Computer vision - AI tasks involving image and video analysis.
- Voice and Audio AI - AI systems that process spoken language or audio signals.
Bear in mind in the rest of this post that I’m ignoring the first three of these completely.
Predictions on Energy Demand and Use
Huge demand is the standard view from the big labs. Here’s Anthropic’s response to the US AI Action Plan:
4. Scaling Energy Infrastructure: To stay at the leading edge of AI development, we recommend setting an ambitious target to build an additional 50 gigawatts of dedicated power by 2027, while streamlining permitting and approval processes
or this from the IEA’s report on Energy and AI: 3
In the Base Case, the total installed capacity of data centres more than doubles from around 100 GW today to around 225 GW in 2030
So if using ChatGPT or Claude is inconsequential, why are there predictions of massive energy use?
Tokens and Joules
To answer this, we need some estimates for the energy cost-per token. This is tricky as the cost per token is dropping very fast:
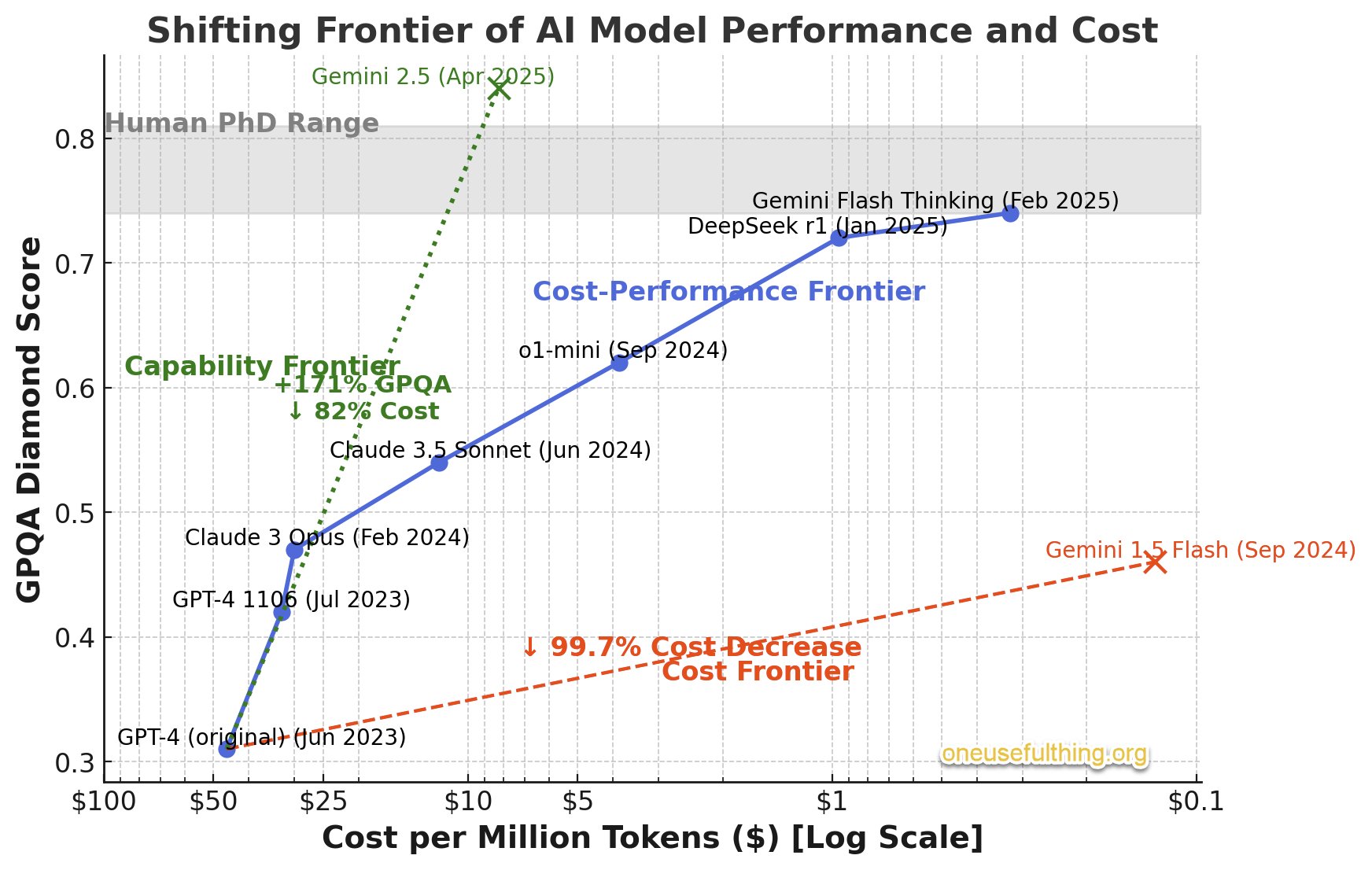
(Source Ethan Mollick) 4
This paper From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference from 2023 estimates 3-4 j/token. A more recent, but less formal, estimate is 0.4 j/token. fwiw I asked ChatGPT-o3 for estimates and references and got numbers back in those ranges (and I did check!). I’m going to use the lower number in the rest of this post, because I want to ver on the conservative side for energy usage.
Multiply up by 10 if you want the higher number, but remember that j/token is reducing.
Update 29/05/25: see my later post on energy per token for more on this. 4-10 J/t would be good for current uses, but as we’re projecting forward a cost that is decreasing, I’m ok with the 0.4 J/t
Armed with that, let’s do some very, very rough and ready estimates of different use cases, starting with real and current ones, and then moving into more speculative ones.
Use Case 1 - standard tasks
Let’s ask Claude to analyse 10 pages of PDF. We can get tokens per file from Simon Willison’s LLM tool.
$ llm 'what are the key themes this this report?' -a EnergyandAI-short.pdf
Based on the executive summary of this International Energy Agency (IEA) report on Energy and AI, the key themes include:
1. **The relationship between AI and energy consumption**:
....etc....
$ llm logs --json -c
"input_tokens": 15871,
"output_tokens": 390,
So for one quick report, that’s ~16,300 tokens and 6520J, or 1.8Wh. Which is approximately nothing.
Let’s push it up a bit by using an LLM in research mode where it might pull in 30 PDFs, and let’s make them all 20 pages
1.8Wh * 2 (20 pages not 10) * 30 (pdfs) = 108Wh 5
That’s about the same as charging an iphone 6-7 times. Still small, but not nothing.
So the summary is that conducting multiple longer queries like this per day is going to add up but the impact is much less than driving a car. One UK gallon of petrol comprises approximately 4.54 litres of fuel and contains the approximate energy equivalent of 43.95kWh of electrical energy. At 44mpg, that’s ~1kWh/mile for a petrol car. Again, numbers choosen to make the maths easy. So 10 of these complex queries is ~1 mile of driving
But I can see a world coming where this goes up fairly fast. If I were to link an LLM to my work Google Drive and do multiple queries/day over spreadsheets and documents the total additional energy use is going to be small in the grand scheme of things, but also not trivial.
Use Case 2 - Software Development
Software development is something where LLMs are absolutely useful right now imo, and also where they are getting better fast.
My average use is at most a few £/day, but let’s look at some outliers on the assumption that as the models get better, average usage will become more like them. Geoffrey Huntley suggests:
Going forward, companies should budget $100 USD to $500 USD per day, per dev, on tokens as the new normal for business
So 100x my usage. Getting to this level means running multiple copies of a coding assistant simultaneously on different parts of a code base, pulling in lots of context etc. It’s not the norm yet, but people are getting value from this level of spend.
Claude pricing for 3.7 Sonnet is $3/million tokens for input and $15/million tokens output and arbitarily assuming a 1:2 input:output ration of tokens gives us 3m input tokens, 6m output for 9m in total/day.
At 0.4 joule/token, this is 1kWh. If you do this every working day for a year (with 4 weeks holiday), it is 240kWh. The same as running a 27W electric appliance 24/7 for a year (e.g. broadband + wifi router).
That $100/day is already much higher than I’m seeing, but when writing this post, I happened to see this on the Zed Discord:
“Talk about token usage 🤔 (433,877,947) last month. 🤯”
That’s heading towards $5k/mth! If someone used this rate every working day it will be ~600kWh/year and 72kg CO2e, but it’s still only the same as 600 miles driving in a petrol car, or one short haul flight per year.
So the use cases above don’t really get us to the massive energy requirements that Schmidt and co predict. Even if every software engineer in the country used £100/day, it’s still not going to do it.
The Panopticon
So far, we’re just talking about text. Vision is going to be way more tokens, especially if the resolution is increased, and video is even more again. As a worked example, Larry Ellison has called for massive survelliance monitored by AI. Let’s take this seriously, which implies a feed from every camera feed into an AI model.
I should be clear that I think this is a terrible idea! But it’s technically feasible now - facial recognition is already better than human level, and LLMs can summarise what’s happening in a video.
Let’s take this image as an example:

$ llm -m gpt-4o 'describe this image' -a IMG_4069.jpeg
The image depicts a scenic landscape with rolling hills and lush green fields under a clear sky.
There are sections divided by stone walls, typical of pastoral settings. In the distance, a hilltop is crowned with a tall monument or tower.
Wind turbines can be seen scattered across the hills, highlighting a mixture of traditional and modern elements in the landscape.
The lighting suggests early morning or late afternoon, giving the scene a warm glow.
$llm logs --json -c
"input_tokens": 775,
"output_tokens": 86,
So at 30fps, low resolution and just treat every frame separately is ~1.49*10^9 tokens/day. But that’s not realistic. For the panopticon we could probably analyse 1 frame a second nearly all the time. That would be ~17m tokens/day/camera
So now we’re at ~700kWh/year/camera.
It’s time for more herioc estimates! The UK is commonly quoted as having 6m CCTV cameras and 1 in 5 households have a doorbell camera, giving another 4m. If we hooked 10m cameras up at 700kWh each per year, we get 7TWh/year, or (so ChatGPT tells me) the total usage of Birmingham, UK. It would emit 1m tonnes of CO2e and need a new 1GW nuclear power plant to drive it.
If we are building Ellison’s dystopia reductions in per token costs will be balanced against increased resolution (quadratic in tokens) and just more cameras. We can go wild with assumptions - drone cameras, car cameras, more CCTV all connected - and total energy usage would depend on how fast the cost per token goes down v the increase in cameras v increase in resolution. Adjust to taste. We could go over 10m cameras very fast.
Just as an example, if you move from 1 frame per second to 30 fps, but assume that you can reduce the input data by 80% by ignoring similar frames etc, you get an annual usage of 108TWh, which is 42% of UK electricity usage! That would make it unfeasible at current efficiency rates, but what I think this thought experiment shows is that there is a plausible route to significant demand.
Now add in personalised AI generated adverts generated on demand, video instead of text as input/output (since we are now post literate), automatic summaries of every video on YouTube etc. Apply a further 10x reduction in per token energy to the estimates, but add back in all the storage and other processing that I’ve ignored and the total impact is still significant if we add in enough new demand 6
The AGI Revolution
But for data centre use to be 99% of all energy use, we need more. What if AI becomes at least human level intelligent or superintelligent? Many people think this won’t happen, but the relevant point for this post is that the people making these predictions of energy demand absolutely do believe that this is were we are going.
What do they mean by this? See Dwarkesh Patel’s vision of AI firms (text or video) or Dario Amodei’s “country of geniuses in a datacenter”
I can’t think of any sensible way of estimating this. We don’t know what a superintelligent AI would take to run since we can’t build it yet.
But this is why Schmidt says that we “have to get it out there” and no longer cares about renewables and why Tony Blair has suddenly turned on net zero. They are building the AI God, and nothing must get in the way. After all, once you’ve built the AI God, it’ll trivially solve climate change
Schmidt further stated that he believes that “we’re not going to hit the climate goals anyway because we’re not organized to do it,” and that he would rather bet on AI solving the problems than constraining the development of the tech and still having the problems anyway
It will be ironic, and unfortunate, if the answer is “reduce energy use”
-
But don’t use Grok. Musk runs the DCs on generators, which are both much more carbon intensive and generate lots of local pollution and he’s using more than is permitted ↩︎
-
These numbers don’t seem to be consistent. Current world electricity generation is measured in terrawatts, not gigawatts, so if data centres are going to use 99% of total generation, it’s not going to be 67 more gigawatts. But let’s roll with it ↩︎
-
Jack Clark has a summary of the report ↩︎
-
For another example: Quern-3 gives much better performance than previous versions on the same hardware ↩︎
-
A reasoning model will require thinking tokens as well, but it’s all rough and ready estimates anyway - remove a few pages of PDFs and it balances out ↩︎