Piotr Mazurek and Felix Gabriel have an amazing post up on LLM Inference Economics from First Principles, which I found on Bluesky.
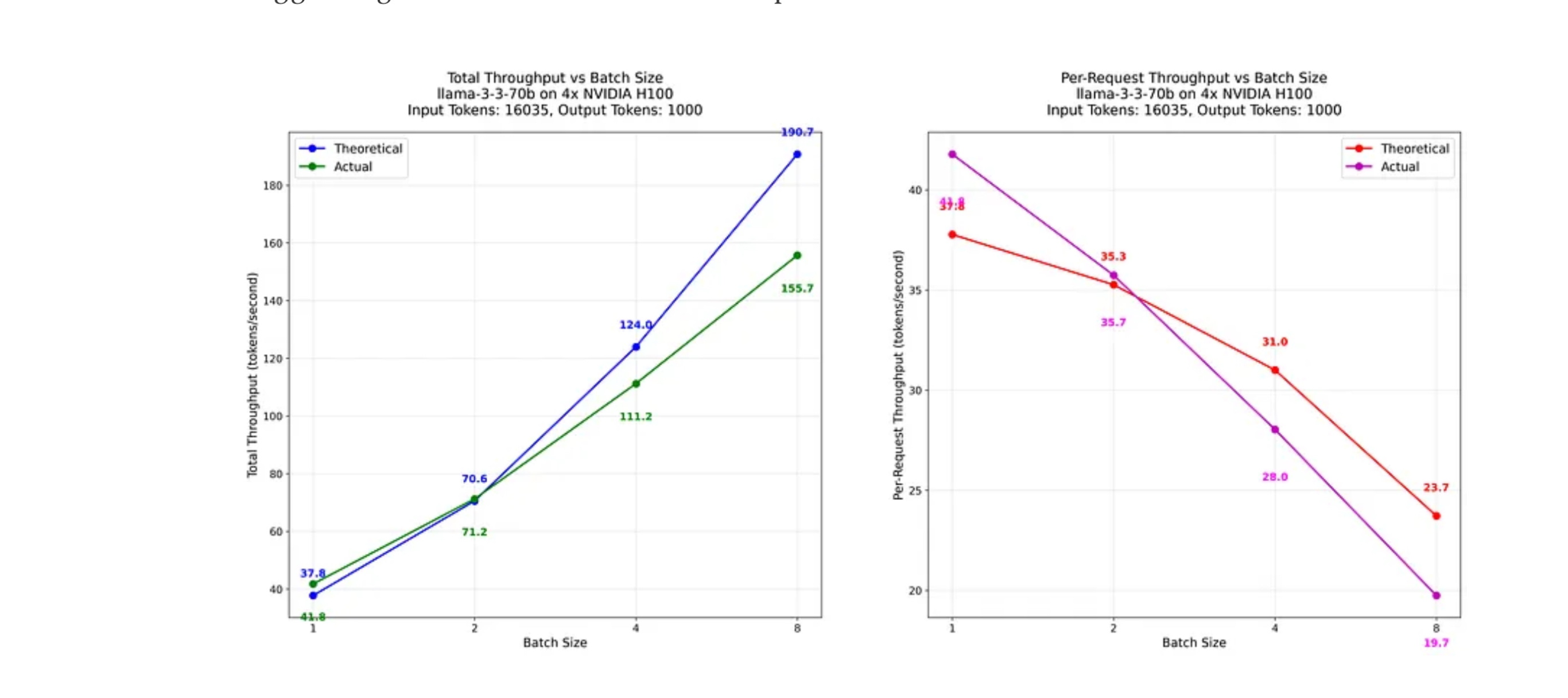
They go into a huge amount of detail about how inference works and how that affects processing speed. But I saw the graph above and thought “we can get energy from that”. And so I asked chatgpt-o3: “Looking at these graphs of throughput at different batch sizes on a 4xH100 80gb cluster, what ranges of power per token do they equate to?”
First up this is based on a large input prompt of 16k tokens. That’s big! But it’s also perfectly reasonable for coding, documents etc. Throughput varies from 41.8 t/s at batch size 1 to 156 at a batch size of 8 on 4xH100s.
Next we need power for the nodes. Bracketing at a higher and low power we get:
| GPU Type | Board TDP | 4-GPU Node | Add ~10% for CPUs, NIC etc |
|---|---|---|---|
| H100 PCIe | 350W | 1.40 kW | ~1.5 kW |
| H100 SXM5 | 700W | 2.80 kW | ~3.0 kW |
These two bounds give us a realistic “best case” (1.5 kW) and “worst case” (3.0 kW) for a well-loaded Hopper box.
For each line, we calculate energy/sec over tokens/sec e.g. 1500 J/s / 41.8 t/s → 36J because 1 kWh = 3.6 MJ, so kWh / M tokens = (J token⁻¹ × 10⁶) / 3.6 × 10⁶
| Batch | J/t @ 1.5 kW | J/t @ 3.0 kW | kWh/million t (1.5 – 3.0 kW) |
|---|---|---|---|
| 1 | 36J | 72J | 10 – 20 kWh |
| 2 | 21J | 42J | 6 – 12 kWh |
| 4 | 14J | 28J | 4 – 8 kWh |
| 8 | 9.6J | 19J | 2.7 – 5.2 kWh |
Even at the most GPU-efficient point (batch 8) the node is burning ≈ 9–19 J per token — 25–50 × more energy than the 0.4 J/token figure I used before.
ChatGPT claims “The culprit is the huge prompt (16 k tokens) plus per-request synchronisation overhead”. Well, the post includes throughput figures for small prompt sizes (2035 in, 300 out) on a four node cluster, so we can do that case:
| Batch Size | Throughput (tokens/s) | J/token @ 1.5 kW | J/token @ 3.0 kW | kWh/million tokens (1.5 – 3.0 kW) |
|---|---|---|---|---|
| 1 | 53.9 | 27.8 J | 55.6 J | 7.7 – 15.4 |
| 2 | 102.9 | 14.6 J | 29.2 J | 4.0 – 8.1 |
| 4 | 182.5 | 8.2 J | 16.4 J | 2.3 – 4.6 |
| 8 | 319.8 | 4.7 J | 9.4 J | 1.3 – 2.6 |
The post also includes a graph of this small prompt case on a single GPU. For this small prompt case, one GPU is faster than four because there’s no communication and syncronisation. This tops out at 2174 at a batch size of 512. Plugging that in, we get 0.69 J/token, which is ballpark to the 0.4 J/token I used before. But it does mean that in practice I should have used 10-20x that for realistic inputs when looking at coding and other long prompt examples.